Actorbase or "the persistence chaos"
Feb 7, 2016
•
Also in:
![]()
You know, everybody out there is talking about Big data, NoSQL databases, reactive programming and so on. There are a lot of buzzwords that are constantly used in this era and the above are some of these.
The idea I will describe to you in a moment is something that I blend my head for a couple of years. My busy life brings me very poor time to work to side projects out of work, so I decide to let some other people to try to transform my idea into a real thing.
But, as usual, let’s start from the beginning.
Why we need NoSQL databases
This section would not be a detailed list of the reasons why we need NoSQL databases. Certainly, we learned so far that the word NoSQL stands for not only SQL. Because what we have learned is that property of SQL database are awesome. Being ACID is such a great thing.
The problem is that a database that tries to guarantee the ACID properties can not scale in a distributed fashion. But, the scalability is what we need to let our massive applications to adapt themselves to the constantly increase of load (Do you really own such an application? I mean, I don’t :P)
So, why not only SQL? Because if we don’t strictly need the relational part, we love to query our databases using SQL!
Which kind of NoSQL database?
There is a variety of types of NoSQL databases. The most famous are the following:
- Document oriented, such as MongoDB
- Graph oriented, such as Neo4j
- Column oriented, such as Apache HBase
- Key-value maps, such as Amazon DynamoDB
More or less, all the above types of database are specialization of key-value maps, in which the values have or not have some form of structure. In my opinion, the killing feature of a database based on the key-value model is that it is naturally ported to scale. Different sets of keys can be store in different nodes, located in different places, replicated many type, and so on.
Then, the only thing you have to choose is how to scale. Which kind of mechanism will manage your key-value couples?
The actor model
The actor model is a well known mathematical model that abstract concurrent and distributed programming into actors. As John Mitchell wrote once:
Each actor is a form of reactive object, executing some computation in response to a message and sending out a reply when the computation is done
The only action that an actor can do are to receive messages (request), to respond to other actors’ requests and to create a new actor if it is needed. The state of an actor is not accessible from outside the actor. So, every operation the actor does can be considered as done in isolation. No race conditions. No mutable shared state. No shared state at all. BOOM!
During its life, an actor can change its interface, which means it can change the type of messages it is able to manage. Virtually, every change of interface corresponds to the creation of a new actor.
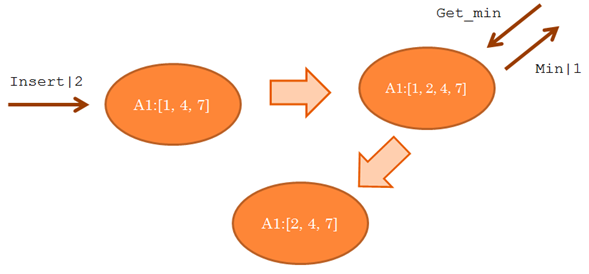
In addition to actors, messages are the other core component of an actor system. There can be different implementation messages. One possibility is to have a message compose of:
- A tag, which means an identifier of the request
- A target, which means an identifier of the actor to which sending the message
- Data, information to be sent within the message

Why are we talking about the actor model? Because actors can be distributed physically in different nodes of a network. In this way it should be simpler to develop a distributed application, also a NoSQL database.
Actor Model + NoSQL database = Actorbase
What the hell can happen if we try to implement a NoSQL database using actors? First of all, we have to choose a NoSQL database model that can fit the actor model. So, let’s choose a key-value map database and let each actor to manage a portion of the map. We can call this kind of actors storekeeper (SK). The number of SK actors that hold a map can be decided by the user with a parameter or it can be derived directly by the number of rows contained into the map.
Every SK actor has one or more ninja (NJ) actor associated to it. This kind of actor executes in a different node of the architecture with respect to its SK actor. Its aim is to replicate the data hold by a SK actor. In case of death of the SK, an available NJ actor will be elected as leader (a.k.a. the new SK actor. Please, refer to Leader Election).
Actors of type storefinder (SF) will receive data modification / query requests from outside and they will forward them to the relative SK. Actors of type SF define something similar to indexes on map keys: the more SF, the less messages will be needed to perform an action to data. The access point to database from drivers and command UIs is an actor of type SF, called the main actor (MN).
Another type of actors that populates our architecture is the warehouseman (WH). These actor have the responsibility to persist to disk information stored into maps by the SK actors.
Last but not least, manager actors (MN) try to maintain the equilibrium inside the SKs. In fact, MN actors will trace the number of entries stored in each map. If their heuristic tells them that some SK actor is under heavy load, they will create new actor of type SK to properly redistribute that load.
The figure below shows a logical schema of the possible interactions between the actor described above.
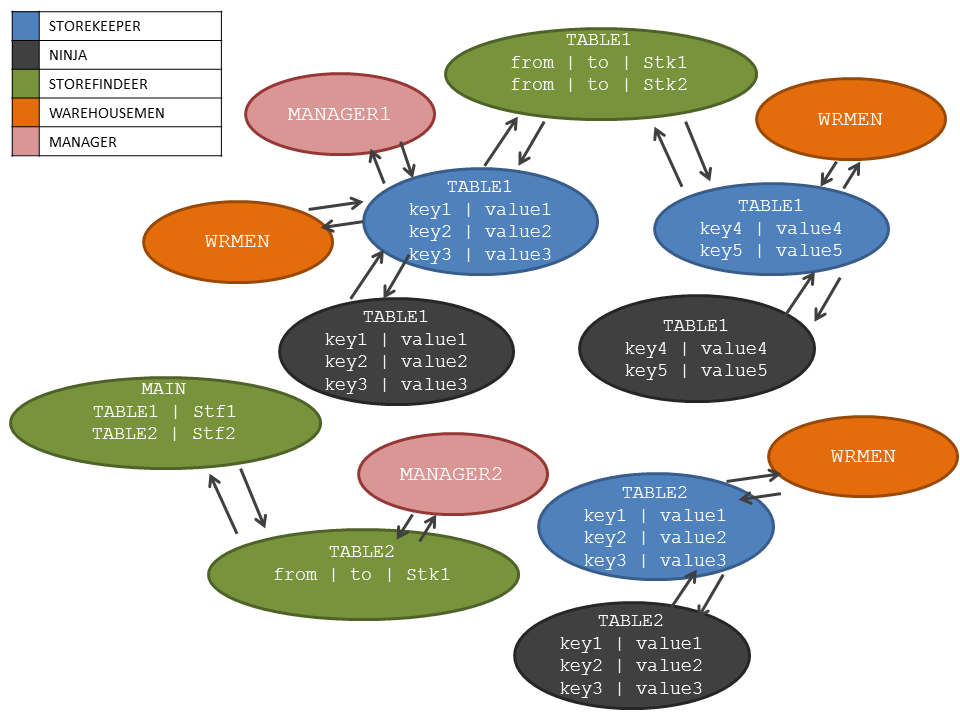
The story so far
Okay, okay, wait a minute. Which is the syntax of the query language? Which are the technical features of this database? Well, this is simply a proposal I gave to my Computer Science students of the Software Engineering course at the Department of Mathematics of the University of Padova.
They have to develop a system that respect the above constraints using Scala as programming language and Akka as the reference actor model. They already produced the document containing the software requirement analysis and they are now approaching to the design and development processes. First prototypes will be available approximately between may and june 2016.
Once the database would be ready, it will be interesting to study which properties it will satisfy. For example, which features of the CAP theorem will it have? Which will be the use cases for such database?
Do you like the idea? Have you some questions or suggestions? Does someone out there want to present us a logo? Let me know in the comments. Cheers!
Add-ons
I am developing my own version of the above specification. The work is slowly proceeding in some way. You can find the repository on my GitHub.
References
- Chapter 14: Concurrent and Distributed Programming. Concepts in Programming Languages, John C. Mitchell, 2002, Cambridge University Press
- Leader Election
- First module home page of the Software Engineering course of the Department of Mathematics, University of Padova (in italian)
- Second module home page of the Software Engineering course of the Department of Mathematics, University of Padova (in italian)