Handling dynamic id objects in Rational Functional Tester
testing
regression-test
rft
Introduction
Functional testing is an discipline that is becoming more and more requested in software industry. A functional test is mainly represented by an automatic navigation inside a UI that checks some properties of that user interface. The growth is probably due to the continuous increasing of the complexity of the UIs.
If you are planning to develop an application nowadays, you will probably choose to develop a single page application based on HTML5 and some Javascript framework. So, testing automatically (or automagically) a UI of this kind means to use some tool that lets you navigate through the application pages inside a browser.
There are three main tools to develop and to execute functional testing, which are:
In this article we will focus on Rational Functional Tester and on a problem that affects it: the recognition of HTML objects with a dynamic id.
Rational funtional tester
I don’t want to have a full dissertation about RFT and its pros and cons. As previously stated, my aim is to focus on a very specific problem, i.e. the recognition of HTML object with a dynamic-id.
How RFT works (sucks…)
In short, RFT gives you a "Studio" application based on top of Eclipse by which a developer can record elements of an
HTML page and can record some actions on them, such as clicks, text editing, and so on. All this stuff is recorded
inside a script, which is a Java class extending a class of the RFT API. Recorded object are represented using other
classes of the RFT API, such as SelectGuiSubitemTestObject which represents a drop down menu, or GuiTestObject, which represents
a simple clickable element. The base class of all the recordable object is TestObject.
Then, the script can be executed and all the action previously recorded are simulated on the HTML page. This lets you to reproduce a user navigation and to test some application properties in the so called functional tests. Differently from Selenium, HTML objects are not managed using directly the Domain Object Model, or DOM. IBM build a structure over the DOM, which is called the Object Map.
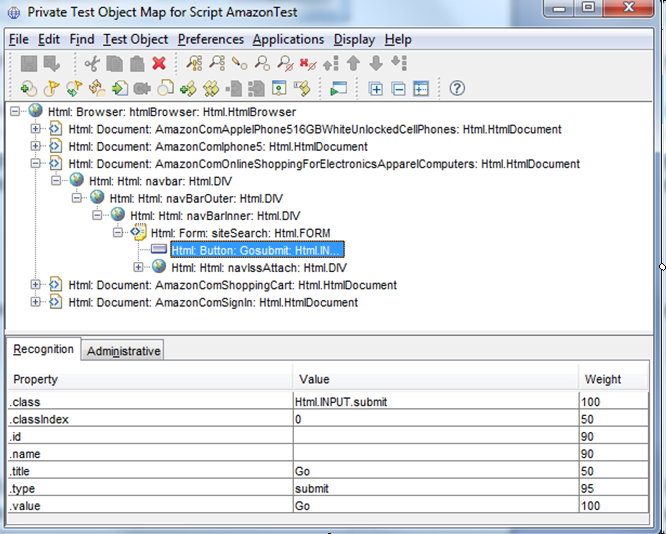
As you can see, every attribute of a recorded HTML element is converted into a twin inside RFT. So, the attribute
id becomes .id, the attribute class becomes .className, and so on. RFT gives weights to every property
and then uses these weights to associate every element, found during execution of a test, to the previously recorded
objects.
Dynamic-id objects: where the plot thickens
So a nice approach, isn't it? No, it is not. It is a f****g damned approach. Why? Because, as every programmer know, there are a lot of framework out of there, that during UI compilation process generate dynamically the ids associated to HTML elements. And what is even worse, every time the page is regenerated or deployed, the *ids are recalculated.
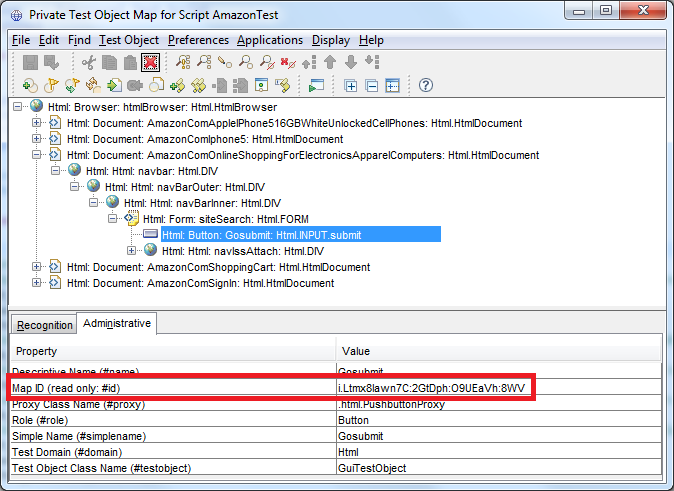
You do understand that if your functional testing tool bases its object recognition algorithm entirely to the id
attribute of an element, you will have a problem. A big problem. Changing the value of the .id property in the object map
does not help: the id could vary so much that it was impossible to express its value with a regular expression.
Is this a dead end? No, luckily it is not.
A subtle escamotage
IBM engineers know how to work. Then they left us a backdoor to enter the Matrix. The type TestObject defines the
method find, that lets us to search for a particular object that satisfies some searching properties.
doc.find(atDescendant(".class", "Html.SELECT"), false);For example, the above code snippet allows you to find every drop down menu object (Html.SELECT) that is contained
inside the object doc. Using the false argument, you are telling to RFT to search among all page elements, and not only among
the ones that you've previously recorded. Then, if the page contains only one element of type Html.SELECT, we have
done. Otherwise, you have to refine your search.
/*
* Finds inside the document 'doc' the drop-down menu
* that contains the option 'name', and then clicks on it.
*/
public static void clickDropdown(DocumentTestObject doc, String name) {
// Prepare finding properties
Property[] props = new Property[2];
props[0] = new Property(".class", "Html.SELECT");
props[1] = new Property(".text", new RegularExpression(".*" + name + ".*", false));
// Find al select items inside the current page
TestObject[] slcs = doc.find(atDescendant(props), false);
// Interact with the element
if (slcs.length > 0)
((SelectGuiSubitemTestObject) slcs[0]).select(name);
}In this case you cannot use directly the .text property in the find method, because the value of the .text property of a
select equals to a concatenation of all its values. So, you have to use a RegularExpression.
Summarizing, once you have found a set of properties that univocally identifies an object, you can use the find method
to obtain the object. If you do not use the .id property in the searching process, the problem of dynamic-id objects
can be avoided.
The other side of the moon
Unfortunately, the using of the find method has many drawbacks. First of all the find method works if and only if the
object you are searching is fully loaded in the page at the time of the search action.
Using the dynamic find technique could be slower than using elements directly recorded by RFT. But, if your UI has dynamic elements’ ids, this is the only way to interact with them.
In this blog there are given some hints to increase the performances of the dynamic find approach.
1) Object Selection : Here you need to find the right set of objects to search on. Let’s call the selected objects as landmarks, which is what we use when we have to move from one place to another in real world.
2) Search Type: Second important decision to make is how do you want to search on the selected object.
3) Property selection : We have found the object on which we want to make a search, we have also figured out the scope of search within the object children hierarchy, now is the time to decide what parameters we like to pass to our search type.
4) Memory cleanup : Last but equally important thing to remember while using objects returned by find is to free the objects as soon as the work is done or whenever you feel that the object might have changed in the AUT as part of some intermediate transaction.